HDB reno service yard breakdown
Service yard
| Floor | $730 |
| Windows | $430 |
| Installation | $80 |
| Electrical works | $45 |
Originally, we had not intended to lay new tiles nor reroute the pipes. That would have saved us $810.
Others
| Piping | $650 |
| Dump debris | $300 |
| Electrical works | $129 |
HDB reno bathroom breakdown
Common bathroom
| Dismantle | $180 |
| Floor | $510 |
| Wall | $1,580 |
| Shower drop | $150 |
| Glass partition | $360 |
| Doorway works (2x) | $280 |
| Glass doors (2x) | $900 |
| Installation | $205 |
| Stuff | $1,122 |
| Electrical works | $51 |
Most expensive stuff:
- Wash basin with cabinet $288
- Toilet bowl $283
- Bath mixer $199
Master bathroom
| Dismantle | $190 |
| Floor | $480 |
| Wall | $1,810 |
| Shower drop | $150 |
| Basin base | $250 |
| Glass partition | $360 |
| Doorway works | $150 |
| Glass door | $450 |
| Window glass | $80 |
| Installation | $295 |
| Stuff | $1,114 |
| Electrical works | $15 |
Most expensive stuff:
- Rain shower set $408
- Toilet bowl $343
- Basin $112
Shared
| Water heater | $299 |
| Hot water piping | $360 |
Lessons
Skip the glass door! It is expensive and needs a lot of room to swing. It also does not flush fully with the door frame! :cry:
We had to reduce the door opening, so the total cost of putting the glass doors is $1,180 for the common bathroom and $600 for the master bathroom!
In hindsight, we should have just gone for aluminium bi-fold doors.
The most expensive part of bathrooms is the tiling. $2,090 for the common bathroom and $2,290 for the master bathroom. If we use cheaper stuff and install only the bare minimum, it'll still take $3k+ per bathroom.
HDB reno kitchen cost breakdown



| Dismantle | $250 |
| Floor | $1,400 |
| Wall | $2,060 |
| Windows | $250 |
| Piping | $100 |
| Stuff | $2,983 |
| Cabinet base | $350 |
| Top cabinets | $2,498 |
| Base cabinets | $2,940 |
| Cabinets (misc) | $723 |
| Table top | $1,860 |
| Electrical works | $1,010 |
There is just one word to describe the kitchen: expensive!
The bare wall/floor alone already cost $3,460!
The cabinets and table-top are very expensive too: a whopping $8,021 in total.
HDB reno cost breakdown
| Kitchen | $16,424 |
| Service balcony | $1,285 |
| Bathroom | $5,667 |
| Msr bathroom | $5,674 |
| Others | $1,079 |
| Accommodation | $910 |
Total a whopping $31,039; about 25% over the budget.
The costs are all-in — including equipment and fixtures. Painting is excluded as it will be done separately.
8088 ADD instruction cycle by cycle
Let's try the ADD instruction next. It is pretty similar.
| Operands | Cycles |
|---|---|
| reg, reg | 3 |
| r8, mem | 9+EA (w: +4) |
| mem, r8 | 16+EA (w: +8) |
Breaking it down to cycles:
| Clk | r,r | r8,[r] | [r],r8 |
|---|---|---|---|
| 1 | D | D | D |
| 2 | E | EA | EA |
| 3 | U | EA | EA |
| 4 | EA | EA | |
| 5 | EA | EA | |
| 6 | EA | EA | |
| 7 | FA | FA | |
| 8 | R | R | |
| 9 | r | r | |
| 10 | r | r | |
| 11 | r | r | |
| 12 | X< | X< | |
| 13 | E | E | |
| 14 | U | U | |
| 15 | Xd> | ||
| 16 | Xa> | ||
| 17 | FA | ||
| 18 | W | ||
| 19 | w | ||
| 20 | w | ||
| 21 | w |
D = Decode, E = Execute, F = Fetch, U = Update.
EA = Effective Address (16-bit), FA = Full Address (20-bit), R = Read memory, W = Write memory, X< = transfer from BIU, X(a/d) > = transfer (addr/data) to BIU.
8088 instructions cycle by cycle
The MOV instruction is a good place to start.
| Operands | Cycles |
|---|---|
| reg, reg | 2 |
| acc, imem | 10 (w: +4) |
| imem, acc | 10 (w: +4) |
| r, mem | 8+EA (w: +4) |
| mem, r | 9+EA (w: +4) |
(imem = an immediate 16-bit offset.)
Breaking it down to cycles:
| Clk | r,r | a8,m | m,a8 | r8,[r] | [r],r8 |
|---|---|---|---|---|---|
| 1 | D | D | D | D | D |
| 2 | E | F | F | EA | EA |
| 3 | Xa> | E | EA | EA | |
| 4 | FA | Xd> | EA | EA | |
| 5 | R | Xa> | EA | EA | |
| 6 | r | FA | EA | EA | |
| 7 | r | W | FA | E | |
| 8 | r | w | R | Xd> | |
| 9 | X< | w | r | Xa> | |
| 10 | E | w | r | FA | |
| 11 | r | W | |||
| 12 | X< | w | |||
| 13 | E | w | |||
| 14 | w |
D = Decode, E = Execute, F = Fetch.
EA = Effective Address (16-bit), FA = Full Address (20-bit), R = Read memory, W = Write memory, X< = transfer from BIU, X(a/d) > = transfer (addr/data) to BIU.
This is purely my guess. AFAIK, Intel does not breakdown how an instruction is executed at the cycles level.
The 8088 bus bottleneck
Intel released the 16-bit 8086 in 1978 and its 8-bit 8088 sibling one year later. The latter is more famous because it was used in the IBM Personal Computer (1981).
The 8088 is rated at 5 MHz, but IBM clocked it at 4.77 MHz. IBM used a single 14.31818 MHz clock source for it (divide by 3) and to drive the NTSC colorburst frequency (divide by 4).
The 8088 can run the same software as 8086, but it does so slower than the 8086 running at the same speed — and much slower than its official timing, in fact.
How come?
Both processors take 4 clock cycles to complete a memory cycle (assuming zero wait state; easy at 5 MHz). The difference is that the 8086 can fetch two bytes at a time (on an even address), but the 8088 can only fetch one byte.
This turns out to be the 8088's biggest bottleneck and the Execution Unit (EU) is basically starved most of the time.
The 8086/8088 is made up of two independent parts, the Bus Interface Unit (BIU) that accesses the memory, and the EU that executes the instructions. The 8086 has 6-bytes code prefetch queue (PQ), and the 8088 4-bytes.
One-byte instructions
Let's take a look at the 8088 executing a stream of 1-byte instructions.
| Clk | BIU | PQ | EU |
|---|---|---|---|
| -3 | P | ||
| -2 | w | ||
| -1 | w | ||
| 0 | w | 1 | |
| 1 | P | D | |
| 2 | w | E | |
| 3 | w | ||
| 4 | w | 1 | |
| 5 | P | D | |
| 6 | w | E | |
| 7 | w | ||
| 8 | w | 1 |
P = Prefetch, w = wait, D = Decode, E = Execute.
Basically, this shows that once the PQ becomes empty, the 8088 is bus-limited and can only execute a 1-byte instruction every 4 clock cycles. The effective clock rate becomes a mere 1.19 MHz.
Note that the PQ never has a chance to fill up! Even if it is full, it would be depleted rapidly — and stay empty.
Two-byte instructions
It gets worse. Sample ADD reg, reg:
| Clk | BIU | PQ | EU |
|---|---|---|---|
| -3 | P | ||
| -2 | w | ||
| -1 | w | ||
| 0 | w | 1 | |
| 1 | P | D | |
| 2 | w | ||
| 3 | w | ||
| 4 | w | 1 | |
| 5 | P | D | |
| 6 | w | E | |
| 7 | w | U | |
| 8 | w | 1 |
U = Update to register file.
A two-byte instruction takes 8 clock cycles, where-as the offical timing would indicate only 2-3! Talk about misleading.
Four-byte instructions
Sample ADD reg, i16:
| Clk | BIU | PQ | EU |
|---|---|---|---|
| -3 | P | ||
| -2 | w | ||
| -1 | w | ||
| 0 | w | 1 | |
| 1 | P | D | |
| 2 | w | ||
| 3 | w | ||
| 4 | w | 1 | |
| 5 | P | D | |
| 6 | w | F | |
| 7 | w | ||
| 8 | w | 1 | |
| 9 | P | ||
| 10 | w | ||
| 11 | w | ||
| 12 | w | 1 | |
| 13 | P | E | |
| 14 | w | U | |
| 15 | w | ||
| 16 | w | 1 |
F = Fetch. 16 cycles instead of the official 4.
Can the PQ be filled?
Only if an instruction takes 4 clock cycles (preferably 8 so that we can refill 2 bytes), and does not reference memory. However, such instructions are very rare.
AAD (60 cycles), AAM (83), MUL (70-113), IMUL (80-154), DIV (80-162) and IDIV (101-184) will allow the PQ to be filled, but they run too slowly to be useful.
So the answer is no, the PQ will never be filled and the 8088 will always be bus-limited.
The Takeaway
To sum up, for non-memory instructions, the 8088 is bus-limited and has a throughout of one-byte per 4 clock cycles.
Smallest hello .COM
When you want full control, you write assembly language:
DGROUP GROUP code, data
code SEGMENT PARA PUBLIC 'CODE'
ASSUME CS:DGROUP, DS:DGROUP
org 100h
main PROC near
mov dx, offset str
mov ah, 9
int 21h
int 20h
main ENDP
code ENDS
data SEGMENT BYTE PUBLIC 'DATA'
str db "hello world", 13, 10, "$"
data ENDS
END main
Building:
masm hello.asm; link hello.obj; exe2bin hello.exe hello.com
Program size? 23 bytes. It can't get any smaller than that! (Well, one
byte less if I use ret.)
I define the segments the old-fashioned way here. With MASM 5.0, we could use simplified segment directives. They are much more convenient.
This follows from my previous post and I'm sure you know by now this is a flawed comparison. But it is true that asm code is easily much smaller compared to the high-level equivalent. The DOS compilers of the time suck at generating 16-bit 8086 code.
It was usual to write the critical parts of a program — the inner loops and video memory access — with assembly language.
And it was usual to write entire programs in asm too, usually due to memory constraints. Main memory is only 640 kB, a 5.25" floppy disk 360 kB and a hard drive 40 MB. Unfortunately, such programs are impossible to port to other platforms. With C, it might still be possible to salvage 50-90% of the code.
Sadly, I spent much of my time writing assembly routines that took way too long to develop, were hard to maintain and to tell the truth, were not that much faster/smaller than their high-level equivalent.
Revisiting 25-years old compilers
BASIC
PRINT "hello world"
Compiled using QuickBASIC 4.50 (1988): 12.00 kB.
Pascal
program HelloWorld;
begin
writeln("hello world");
end.
Compiled using Turbo Pascal 5.0 (1988): 1.80 kB
C
#include <stdio.h>
int main(void) {
printf("hello world\n");
return 0;
}
Compiled using Microsoft C Optimizing Compiler 5.10
(1988) with /Ox flag: 7.05 kB
Code generated:
_main PROC NEAR
mov ax, OFFSET DGROUP:$SG195
push ax
call _printf
add sp, 2
sub ax, ax
ret
nop
_main ENDP
The takeaway
This is an incorrect comparison between compilers, much less between languages. A bunch of us were trying to find the "best" (meaning fastest and smallest) general-purpose computer language.
At that time, our school was using GW-BASIC in our computer curriculum. We scoffed at it because it was an interpreter. We wanted to use a real language that could generate a real program, i.e. an EXE file.
It was surprising for me that C was not automatically better than Pascal. As in, any C compiler should generate better (faster/smaller) code than any Pascal compiler.
In fact, it was the other way round: Turbo Pascal beats everything else hands down in virtually all cases: compilation speed, program size and execution speed, although the last one was only true because I wrote such inefficient C programs.
Still, I resisted using Turbo Pascal for a few years because of its reputation as an introductory programming language. I wanted to use a real programming language, you see.
Extracting floppy disk images
I was looking for old DOS applications on the net and found that many of them were packaged as floppy disk images with the extensions .ima, .img and .imz.
From what I read, IMA and IMG files are one and the same. However, DosBox, an open-source x86 DOS emulator, could mount IMA files directly, but it was not able to do so for IMG files.
I didn't want to use the shareware WinImage (30-days trial) to read the IMG files, and after some more googling, I found that the open-source mtools could do it:
mcopy -i file.img -ms :: dest_dir
This is nice, because I could script this to extract over 300 images — imagine doing it one by one!
mtools could read IMA files too, but it did not recognize IMZ files. Luckily, after some more googling, I found that IMZ files are simply gzipped IMG files.
mv file.imz file.img.gz gunzip file.img.gz mdir -i file.img ::
It worked!
Using with DosBox
I still prefer to extract the files out from an IMA file even though DosBox supports mounting it directly.
One of the reasons is that DosBox does not support "swapping" IMA files mid-stream, which is sometimes needed for installation. In the long past, programs come in multiple disks and we must swap disks as we install them. :lol:
(Note that most of the time, we can copy all the files from the disks to one single dir.)
My trick is to mount a directory dos_floppy as A: and use Windows Explorer to copy the disk image in as needed. Then, we press ctrl-F4 in DosBox to flush its disk cache. This works for me so far.
C and overly aggressive optimization
This code tries to test if an integer has overflowed:
int v;
if(v > v + 1)
abort();
printf("no overflow\n");
But it will not work. The if is removed by the
compiler because signed int overflow is undefined, and the compiler has the
leeway to optimize it away. And it does.
void f(int *p) {
int v = *p;
if(p == NULL)
return;
*p = 4;
}
f(NULL);
It crashes on some compilers. How can it be? We checked for NULL explicitly!
Guess what? It is removed by the compiler.
The reason? Dataflow analysis that eliminates useless NULL pointer checks. If a pointer has been dereferenced, it clearly cannot be NULL, so the check is removed!
IMO, C compilers are getting too aggressive in their optimizations. They have to be for a few reasons: arms race with other compilers, to handle machine-generated C code and macro expansions efficiently.
But when it is enough to raise an eyebrow, you know that it has gone too far. (This is the "eyebrow test".)
C and pointer aliasing
Most low-level programmers who use extensive typecasting will be surprised by the code below.
void check(short *s, long *l) {
*s = 5;
*l = 6;
if(*s == 5)
printf("strict aliasing problem\n");
}
int main(void) {
long v[1];
check((short *) v, v);
return 0;
}
*s == 5. Another example:
uint32_t swap_words(uint32_t arg) {
uint16_t *sp = (uint16_t *) &arg;
uint16_t hi = sp[0];
uint16_t lo = sp[1];
sp[1] = hi;
sp[0] = lo;
return arg;
}
Does not swap. The reason? Strict aliasing rule.
The way to make it work is to cast to void *, char
* (one-way only), use memcpy() or use union.
I think compilers are invoking this rule too readily. In some cases, they can clearly see the pointers are aliased, yet they still follow this rule strictly.
Personally, I think this should be off by default, and turned on explicitly by the programmer in timing-critical code. This is the principle of no-hidden-surprises. (C++ violates this principle readily.)
C and pitfalls
C has many pitfalls for a programmer to fall into — although they are very tame compared to C++.
Guess the result:
int v = 1;
printf("%d\n", v << 32);
How about this:
int f(void) { printf("f"); return 1; }
int g(void) { printf("g"); return 2; }
int main(void) {
printf("%d\n", f() + g());
return 0;
}
Something similar:
int f(void) { printf("f"); return 1; }
int g(void) { printf("g"); return 2; }
int main(void) {
printf("%d %d\n", f(), g());
return 0;
}
Do you know the dark corners of C?
In C, there are four categories of behaviour:
- Well-defined / deterministic
- Implementation-defined
- Unspecified
- Undefined
The difference between implementation-defined behaviour and unspecified behaviour is slight but important.
Implementation-defined behaviour must be consistent and documented. Unspecified means that the compiler can choose between one of the alternatives depending on the context.
Some examples of implementation-defined behaviour:
- two's complement integers
- IEEE-754 floating point numbers
charis either signed or unsigned
Last piece of code:
int v = 1;
v = v++;
printf("%d\n", v);
Does the term sequence point come into your mind?
C and integer promotions
In C, all integer operands smaller than int in an expression are promoted to an int first.
Note: this is not true in C++.
This rule is very simple and effective. Until we come to signed and unsigned mixed-size ints.
short a = -1;
int b = 1;
printf("%d\n", a < b);
This will print out 1. What about this?
unsigned short a = -1;
int b = 1;
printf("%d\n", a < b);
It prints 0. Why?
Because there is a rule that says if the type of the operand with signed integer type can represent all of the values of the type of the operand with unsigned integer type, then the operand with unsigned integer type is converted to the type of the operand with signed integer type.
Despite assigning -1 to a, it has the value 65535 (it is
unsigned, remember). 65535 can be represented as an int, so a
is promoted to an int. 65535 is not < 1, so it prints 0.
This is a trap that escapes most eyes.
You may think you'll never encounter this because you don't use
short. Well, there is something similar in 64-bit programming:
unsigned int a = -1;
long b = 1;
printf("%d\n", a < b);
It prints 0 if long is 64-bit.
The takeaway
Signed and unsigned mixed-size int do not play well together.
C and the 32-bit sweetspot
32-bit platforms are a natural sweetspot:
| int | 32-bit |
| data pointer | 32-bit |
| function pointer | 32-bit |
| long | 32-bit (typically) |
| long long | 64-bit |
32-bit integers can hold most real-world values (+/-2 billion) and 32-bit pointers can address 4GB of memory — sufficient for most programs.
What is nice is that integers and pointers are physically interchangable because they are of the same size. You can squeeze an integer into a pointer and vice-versa.
For callbacks, we can simply define a void * to pass in an
arbitrary argument — lthough it is not strictly C89 compliant.
Unfortunately, this is not true for most 64-bit platforms:
| int | 32-bit |
| data pointer | 64-bit |
| function pointer | 64-bit |
| long | 32-bit or 64-bit |
| long long | 64-bit |
Depending on the platform, long is either 32-bit (Microsoft
Windows) [the LLP64 model] or 64-bit (Linux) [the LP64 model]. There are
pros and cons, but what it means is that we can no longer use
long as-is!
(Note: int is 64-bit on an ILP64 platform. However, it is
not fashionable nowadays.)
C99 has to invent a new type, intptr_t that is guaranteed to
be the bigger of int and data pointer.
However, it is better to create two unions:
typedef union {
int v;
void *p;
} intptr_ut;
typedef union int_ptr_fn_ut {
int v;
void *p;
union int_ptr_fn_ut (*fn) (union int_ptr_fn_ut *arg);
} int_ptr_fn_ut;
The first one is an alternative to intptr_t. It just makes
it easier to use without lots of typecasting.
The second one is to allow a function pointer to be used. In the C standard, data and function pointers are not interchangable, although one tends to overlook that for 32-bit linear address space.
printf
printf() and family gets harder to use. Suddenly, we have to
get the types right.
int v;
long l;
void *p;
printf("%d %d %#x", v, l, p); // works on 32-bit system
printf("%d %ld %#p", v, l, p); // needed on 64-bit system
The takeaway
32-bit programming can make one lazy and take data sizes for granted. However, that time is past. We now have to get the data types correct.
My 100% unscientific living space needed
| Base | 20 sqm |
| First two adults | 50 sqm |
| Subsequent adults | 20 sqm |
| First child | 30 sqm |
| Subsequent children | 20 sqm |
What this means:
| One adult | 45 sqm |
| Two adults | 70 sqm |
| Three adults | 90 sqm |
| Two adults and one child | 100 sqm |
| Two adults and two children | 120 sqm |
| Four adults and three children | 180 sqm |
Singapore is getting stingy with their flat size. No downsize my foot.
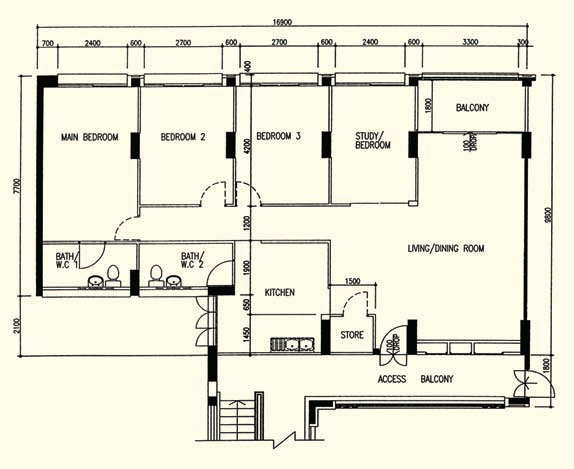
Flaws in this flat design
This is a variant of the earlier 5-room floor plan that I like.
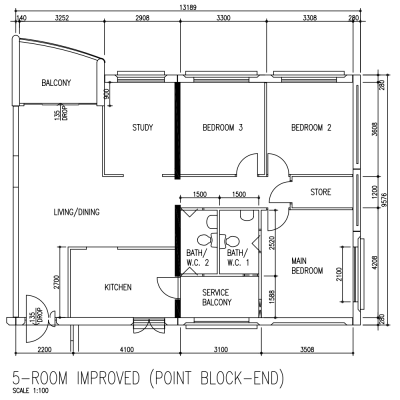
Once you know your own HDB flat well enough to know what you like and dislike about it, you can easily read the other floor plans to see whether you'll like the flat or not.
Likes
The door to the common toilet is not within the kitchen.
The door to the rooms do not open to the living room. (There is a hallway.)
There is a short passageway at the main door.
The store room is tucked away neatly.
There is no bomb shelter and rubbish chute.
Dislikes
The kitchen only has one small outside window. It will be dim.
The toilets do not have outside windows. They will be dim and hard to dry.
The toilet bowl is in the middle of the toilets.
Comparing HDB floor plans
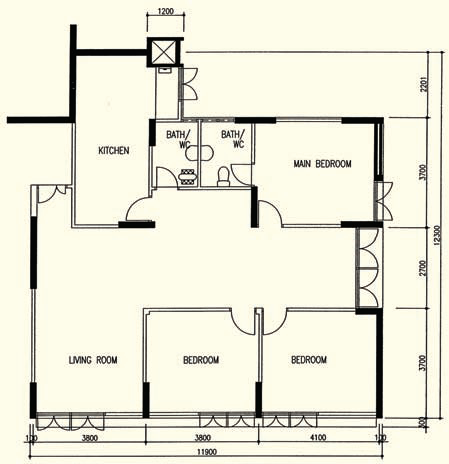
123sqm 5-room
Early design from the 70s. Only has basic rooms, but every area is pretty big. There is no wasted space!
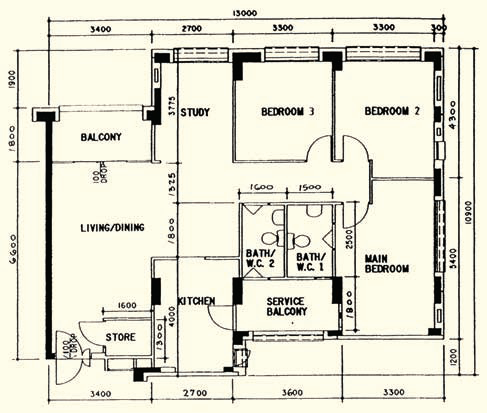
122sqm 5-room
Early 90s design. The rooms are smaller, but now there is a study room, a balcony and a store. Every inch is utilized.
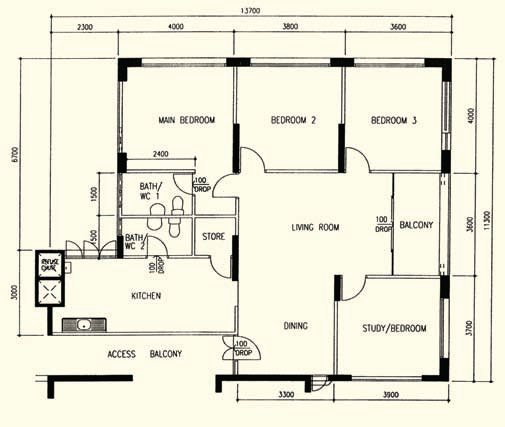
123sqm 5-room
Mid-90s design. You've seen this before. Differences: hallway, service balcony, 2-door toilet.
Unlike the others, this design has some flaws and wasted space. However, it is still my favourite 5-room design. :-D
Which one do you like?
HDB floor plans that I like
I found a website Teoalida's Website that contains many HDB floor plans from the 1960s to 2010 (but it is by no means comprehensive). The owner, Teoalida, has a hobby of collecting HDB floor plans.
These three are my favourites:
123sqm 5-room
143sqm EA
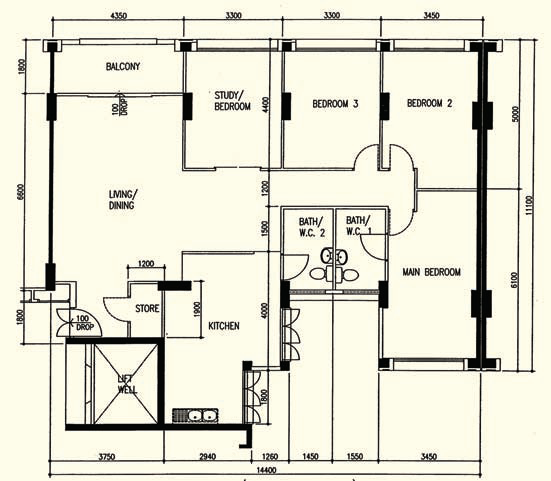
146sqm EA
All three are designed during the mid-90s.
There is one particular feature in them that I like very much. Can you see what it is?
No, it's not just the size.
Size matters, but the layout is important too.
Audio toolchain on RHEL 6
The non-open source Nero AAC Encoder is recommended to encode AAC. However, it only accepts wav files, so we use ffmpeg as a decoder.
Step one: download and build ffmpeg.
Step two: download pre-built Nero AAC encoder.
And we are done:
ffmpeg -i input -f wav - |\ neroAacEnc -ignorelength -if - -of audio.mp4
Pretty easy! :nod:
Messed up repo on my RHEL 6
I'm running RHEL 6.4. However, the files in /etc/yum.repos.d are pointing to RHEL 6.1 repos!
This is obviously a problem.
When I install a new package, it is taken from the 6.1 repo. If it requires an older dependency than what is installed, yum will fail.
This is the reason why I have issues with libexif.
The version in RHEL 6.4 is 0.6.21-5, but the version in RHEL 6.1 is 0.6.16-4.1.
I changed all the "6.1" to "6.4". But yum still failed to work.
I took a closer look: the links to the errata were commented out! They are needed to get the latest packages.
I uncommented the errata links and now yum sees the latest packages. I believe the repo is structured such that the base repo contains the packages that come with 6.4, and the errata are the updates.
Mystery solved!
The last step is to issue this to keep the system up-to-date:
sudo yum update
Long road to avisynth on RHEL 6
avisynth is a powerful open-source video frame server that allows many video manipulation with its support for plugin and scripting.
Unfortunately, it is a 32-bit Windows program, at least for the stable 2.5.8 version that we want to use.
Hence my journey to make it run on 64-bit RHEL 6.
Wine
For some reason, I thought Wine was not available on RHEL 6, so I downloaded the source from WineHQ. Since I'm using 64-bit RHEL 6, I built the 64-bit version.
wine doesn't work, but wine64 does. That's normal, I thought. I compiled the 64-bit version, after all.
Then, I tried to run some Windows applications. They did not run and there were no error messages.
After a long while, it finally dawned to me that I needed to build the 32-bit version of Wine because I was going to run 32-bit Windows programs!
It was not clear to me that I should not build 64-bit Wine just because I was running on 64-bit RHEL. Rather, it depends whether I want to run 32-bit or 64-bit Windows.
Unfortunately, I was unable to build the 32-bit Wine because I lacked the 32-bit libX development tools.
yum stopped me from installing it because "it is already installed". Well, you checked the 64-bit version, you dumb program!
After trying for some time, I realized I could look for a prebuilt wine. Hmm, it looks like wine is available on RHEL 6!
I finally tried:
sudo yum install wine
Surprisingly, the wine package was found! It could have saved me one morning's work.
But it did not install. It complained it could not find libexif.
The story of libexif
I have libexif-0.6.21-5.el6_3.x86_64 installed. It is 64-bit. Wine requires the 32-bit version. No issue, just install it:
sudo yum install libexif.i686
yum complained "Multilib version problems found". The reason is that 32-bit version is older (0.6.16-4.1.el6). No go.
This did not work either:
sudo yum install --setiot-protected_multilib=false libexif.i686
After trying for a long time, I finally realized (again) I could look for a prebuilt libexif.
But I found something better: I could download the source RPM from RedHat repo directly. It is safer too.
Build it:
rpmbuild --rebuild libexif-0.6.21-5.el6_3.src.rpm
This builds the x86_64 version, I want the i686 version, so let's try again:
rpmbuild --rebuild --target=i686 libexif-0.6.21-5.el6_3.src.rpm
And install it:
sudo rpm -ivh libexif-0.6.21-5.el6_3.i686.rpm
No surprise, it failed. :lol: The reason was that it is already installed — well, only the 64-bit version!
No issue, just force it through:
sudo rpm -ivh --force libexif-0.6.21-5.el6_3.i686.rpm
(This caused yum to complain every time I ran it, because the 32-bit and 64-bit versions are still not in sync. Let's ignore it for now. :-P)
End in sight at last
I was finally able to run avisynth using avs2yuv as a conduit:
wine avs2yuv test.avs -o test.out
test.avs is a one-liner avisynth script:
version()
And I got a nice error message:
failed to load avisynth.dll
The reason is that avisynth requires the VC++ 6.0 redistributable files. No issue, just download from Microsoft's website and install it. (The latest one is from VC++ 6.0 SP6 from April 2004.)
And it finally worked. *phew*
To do something useful, we need to chain it to a video encoder.
x264
x264 is not available on RHEL. Not an issue, just download the source and build it. (This is a recurring theme.)
Chain to x264
The start of a usable tool chain:
wine avs2yuv test.avs - | x264 --stdin y4m --output test.mkv -
It works!
And this is just the video tool chain. I still need to create the audio tool chain.
Why not HandBrake?
On video encoding forums, HandBrake is said to be for beginners.
What is wrong with using HandBrake?
The first problem is that the encoders in HandBrake are statically linked. This means that we cannot add new encoders or upgrade them as we like. We need to upgrade HandBrake.
However, HandBrake is released infrequently. The current version 0.9.9 was released in May 2013. The previous version 0.9.8 was released one year earlier in July 2012.
We can opt for the nightly builds, but they are not guaranteed to be stable.
The second problem is that HandBrake does not allow external filters. We are restricted to the built-in ones. If we want to do any kind of processing, however simple, we cannot use HandBrake.
Ultimately, HandBrake itself is "just" a frontend to the video and audio encoders. Why add a middleman? (However, this is strongly discounting its convenience.)
The alternative is to build our own video/audio processing toolchain! But be warned: it is not for the faint-hearted. :lol:
Encoding and CPU affinity
The H.264 encoder x264 spawns threads to speed up encoding. The default formula is 1.5 * #logical processors. However, it is at a small cost to size (though not quality).
The best is to use just two threads. It is slow to encode one video, but we can encode multiple videos in parallel at full speed.
However, we could encounter "core-thrashing", where the OS keeps changing the core to run the app. Speed will fall off the cliff because the data cache is always invalidated.
The answer is to bind the app to the cores explicitly:
taskset -c 2,3 ./encode.sh
We need to read /proc/cpuinfo to make sure we assign two logical processors on the same physical CPU!
taskset can be used on running processes, but it looks like it has no effect on existing threads, and only affects new threads that the process creates.
Running HandBrake on RHEL 6
HandBrake is not available on RedHat Enterprise 6.
However, the instructions to compile it from the source is on HandBrake's website itself.
And it works!
Time to put my aging but still powerful Xeon X5450 workstation to good use. :-D
I also needed to use mkvmerge. Luckily, the mkvtoolnix package is available, although it is an older version (4.9.1 instead of 5.1.0).
Strangely, the package does not have mkvinfo, which is useful to see contents of the MKV file.
Bouncing and bouncing
How do we detect physical hardware button presses? Does this code work?
if(hw_btn_pressed) handle_btn();
Sort of, but we'll quickly find that handle_btn is called
more than once.
The reason is that when a button is pressed, it takes a while before it becomes stable. We need to wait for the button to be debounced.
First, we create a generic button object:
typedef struct {
bool_t (*is_pressed) (void);
int debounce_ticks;
bool_t state;
int countdown_tick;
} btn_obj_t;
bool_t get_btn_state(const btn_obj_t *btn) {
return btn->state;
}
void ctrl_btn_state(btn_obj_t *btn) {
if(btn->countdown_tick > 0) {
if(--btn->countdown_tick == 0)
btn->state = btn->is_pressed();
return;
}
if(btn->state != btn->is_pressed())
btn->countdown_tick = btn->debounce_ticks;
}
Then, we define the buttons:
bool_t is_btn_a_pressed(void) { return is_hw_btn_a_pressed; }
bool_t is_btn_b_pressed(void) { return is_hw_btn_b_pressed; }
btn_obj_t btn_a = {
is_btn_a_pressed,
MS_TO_TICK(20)
};
btn_obj_t btn_b = {
is_btn_b_pressed,
MS_TO_TICK(100)
};
It should be obvious how the functions are to be used.
Simple timers
One of the fundamentals of real-time systems is timing. We will set up a periodic interrupt to run every x microseconds and increment a counter in it. That gives us the basics of timing.
However, it is only the start. For one, it overflows too quickly. Suppose it interrupts every 500us, a 16-bit counter will overflow in 32.7s!
We prefer to use 16-bit values because we are running on a 16-bit CPU. Using 32-bit values will increase the code size and reduce performance.
We have to "step-down" and introduce a few slower timers at the same time.
Typically, we will have a "tick" timer that the system is running at. That is the speed of the main while loop and is typically in milliseconds.
Then, we have the 1sec and 1min timers.
unsigned int timer_hr_tick;
unsigned int timer_tick_countdown;
unsigned int timer_tick;
unsigned int timer_1s_countdown;
unsigned int timer_1s;
unsigned int timer_1m_countdown;
unsigned int timer_1m;
void interrupt isr(void) {
++timer_hr_tick;
if(++timer_tick_countdown == NUM_INTERRUPTS_PER_TICK) {
timer_tick_countdown = 0;
++timer_tick;
if(++timer_1s_countdown == NUM_TICKS_PER_SEC) {
timer_1s_countdown = 0;
++timer_1s;
if(++timer_1m_countdown == 60) {
timer_1m_countdown = 0;
++timer_1m;
}
}
}
}
Note that this code assumes there is an integral number of ticks per second.
There is still the issue of overflow. If each tick is 10ms, the tick timer will overflow in 10mins. The second timer will overflow in 18 hours and the minute timer will overflow in 45 days.
Controlling several LEDs
The previous code structure allows us to control one LED. What if we need to control two? Do we repeat the entire code? How about three LEDs?
It is easy to duplicate the code when writing, but it is a nightmare to maintain. At some point, we have to generalize the code.
typedef enum {
LED_STATE_OFF,
LED_STATE_ON,
LED_STATE_BLINK,
LED_STATE_SLOW_BLINK
} LED_STATE_T;
typedef struct {
void (*on) (bool_t on_flag);
int blink_tick;
int slow_blink_tick;
int state;
int tick;
} led_obj_t;
void set_led_state(led_obj_t *led, int state) {
led->state = state;
}
void ctrl_led_state(led_obj_t *led) {
switch(led->state) {
case LED_STATE_OFF:
case LED_STATE_ON:
led->on(led->state);
break;
case LED_STATE_BLINK:
if(++led->tick >= led->blink_tick * 2)
led->tick = 0;
led->on(led->tick >= led->blink_tick);
break;
case LED_STATE_SLOW_BLINK:
if(++led->tick >= led->slow_blink_tick * 2)
led->tick = 0;
led->on(led->tick >= led->slow_blink_tick);
break;
}
}
Here, we generalize the two functions so that they take in a
led_obj_t. The next step is to instantiate for each LED:
void led_a_on(bool_t on_flag) { hw_led_a(on_flag); }
void led_b_on(bool_t on_flag) { hw_led_b(on_flag); }
led_obj_t led_a = {
led_a_on,
MS_TO_TICK(250),
MS_TO_TICK(1000)
};
led_obj_t led_b = {
led_b_on,
MS_TO_TICK(250),
MS_TO_TICK(1000)
};
The third part is using them:
while(TRUE) {
ctrl_led_state(&led_a);
ctrl_led_state(&led_b);
...
}
To set the state:
set_led_state(&led_a, LED_STATE_ON); set_led_state(&led_b, LED_STATE_BLINK);
The code works for controlling LED, but there is a possible issue if we want to use this code structure for other hardware switches. Can you spot it?
Controlling a LED
One of the simplest tasks is to control a LED. However, it is not just a matter of on and off. we often need to make it blink.
typedef enum {
LED_STATE_OFF,
LED_STATE_ON,
LED_STATE_BLINK,
LED_STATE_SLOW_BLINK
} LED_STATE_T;
#define LED_BLINK_TICKS MS_TO_TICK(250)
#define LED_SLOW_BLINK_TICKS MS_TO_TICK(1000)
static int led_state;
static int led_tick;
void set_led_state(int state) {
led_state = state;
}
void ctrl_led_state(void) {
switch(led_state) {
case LED_STATE_OFF:
hw_led(FALSE);
break;
case LED_STATE_ON:
hw_led(TRUE);
break;
case LED_STATE_BLINK:
if(++led_tick < LED_BLINK_TICKS)
hw_led(FALSE);
else if(led_tick < LED_BLINK_TICKS * 2)
hw_led(TRUE);
else
led_tick = 0;
break;
case LED_STATE_SLOW_BLINK:
if(++led_tick < LED_SLOW_BLINK_TICKS)
hw_led(FALSE);
else if(led_tick < LED_SLOW_BLINK_TICKS * 2)
hw_led(TRUE);
else
led_tick = 0;
break;
}
}
Note that we use a macro MS_TO_TICK to convert from ms to
ticks. This is to avoid hardcoding the duration of each tick.
set_led_state() is called to set the LED state.
ctrl_led_state() is called in the main
while(TRUE) loop.
The code is meant to be readable and not clever. Otherwise, it could be shortened by quite a bit.
The skeleton state machine
This is the skeleton state machine for a 16-bit CPU:
static bool sm_flag;
void interrupt isr(void) {
if(hw_timer_0) {
hw_timer_0 = 0;
sm_flag = TRUE;
}
}
int main(void) {
init();
while(TRUE) {
if(sm_flag) {
sm_flag = FALSE;
handle();
}
}
return 0;
}
All programs have the same skeleton. The program logic is in
handle().
USB 3.0: the need for speed
My existing PCs only have USB 2.0. I get a transfer read rate of 32 MB/s from my external HD. I thought it was decent.
Until I used USB 3.0.
132 MB/s.
Wow.
My most powerful PC ever
| CPU | 2x Xeon E5-2670 2.6 GHz |
| RAM | 16 GB DDR3-1600 |
| HD | 1 TB SATA 7200RPM, 128 GB SSD |
| DVD | 8x DVD R/W |
| Video | Nvidia Quadro K2000 2 GB |
Wow.
Lessons from 360p encoding
720p and 1080p videos encode better than 480p videos.
The show must have chapter stops before encoding. The reason is that they guaranteed to be IDR frames, so we can later cut at that exact frame. This is important if we want to cut away the opening, closing and preview.
The frame rate is sometimes not set correctly. The container specifies 29.97 fps even though the video is 23.976 fps. The built-in Android video player does not play such videos properly (a/v out of sync).
Does the source video have black bars? If so, we need to crop and adjust the width manually, keeping the height at 360px.
Is the source video exactly 4:3 or 16:9? Most are, but some are slightly off (due to cropping) or in 1.85 aspect ratio. We got to set the width manually.
Is the source grainy? This is true especially for old shows. If so, we apply some denoising. I use 3:2:5:5 for slightly grainy shows and 3:2:7:7 for fairly grainy shows.
(3:2 is medium spacial [single frame] strength. 5:5 is "medium" temporal [multi-frame] strength.)
We must save per-show settings. This is so that we can re-encode the shows easily.
360p portable edition
I have begun to create the "portable 360p edition" of some of my anime. 360p means either 640x360 (WS) or 480x360 (4:3).
The saving is tremendous. A 24-mins 1080p video weighing at 701 MB is only 75.5 MB after conversion!
Anime has little fine details, so it is easy to compress. The quality remains pretty good, although a bit soft.
And it is possible to make the file even smaller!
For a 24-min anime, the opening and closing typically take 1m30s each, and the next episode preview 30s. If we cut them off, we save 3m30s. That would make the file around 15% smaller (64.2 MB).
Not too bad.
More HD blues
643 bad blocks (4kB each). That is the result after 45 hours of read/write testing. I marked them as bad and continue to use the HD. To throw away 2 TB just for 2.5 MB of bad blocks? It's such a waste. Let's see how long I can continue to use the HD.
Just when I thought I got over my HD error, I found more HD issues. This time, with my old portable 80 GB HD.
I was using it to transport media files. Some of them were corrupted subtly. I didn't expect there to be no HD errors at all. Just silent corruption.
As a result, I did not notice the errors until I did a MD5-sum and compared against the original files. They were different! For some time, I thought the original files were corrupted!
One more HD paper-weight.
HD dying again
After just 1.5 years of 24/7 service, my HD is dying again.
I knew something was wrong when I was not able to read some files. I then took a look at the SMART status: it indicated some read errors. Apparently, it was not considered severe enough to warn the user.
Also, it looks like the bad blocks are not remapped by the drive because the write succeeded! (The HD automatically remaps bad blocks only on write failures.)
At least this was detected relatively early, before even more damage was done.
badblocks shows there are 2,188 bad blocks, or just over 2 MB. This program runs very slowly, but it slows down even more over the bad blocks. It took over 15 hours for the scan to finish.
I haven't tried it, but this seems to be the command to do it:
e2fsck -c -c -k -C 0 /dev/sda7
I'm backing the data out before I mark the blocks as bad.
Cause?
I'm wondering what is causing the HD to fail so quickly?
Is it because I run it 24/7?
Or was it because the HD crashed due to improper shutdown? (Which happened a few times.)
My x264 settings
It doesn't get any simpler than this:
veryslow preset ref 4 merange 16 aq-strength 0.7 psnr 0 ssim 0 threads 2
The veryslow preset sets most of the settings properly already.
It sets 8 ref-frames and use a ME range of 24. I just lower them.
Update (Sep 2013): I am now using 6 ref-frames and merange of 24.
Decoding x264 output
x264 outputs some statistics at the end of encoding. It is good to understand what some of the lines mean.
x264 [info]: frame I:6 Avg QP:20.69 size: 45383 x264 [info]: frame P:365 Avg QP:23.31 size: 21380 x264 [info]: frame B:1158 Avg QP:27.40 size: 7032
This shows the QP for the I, P and B frames. The difference between them is always 3-4. The CRF supplied will determine the QP of the I frame, although sometimes it determines the QP of the P frame instead.
Based on my limited video comparisons, I found that QP of 18-19 for P frame is "transparent" for DVD. That means using a CRF of 15-16.
I frames are twice the size of P frames, and B frames are significantly smaller.
x264 [info]: consecutive B-frames: 0.5% 1.7% 8.0% 53.4% 26.2% 9.8% 0.5% 0.0% 0.0%
This shows how many consecutive B-frames are used, starting with 0. I see mostly 3-5 B-frames being used. I always specify 8 B-frames.
x264 [info]: ref P L0: 55.9% 19.9% 16.8% 6.6% 0.7% 0.0%
This shows the number of reference frames being used. The last two numbers should be ignored. I always specify 4 ref-frames, although we can use 8 at 720p and below. Based on the statistics, there should be little value in using more than 4 ref-frames.
x264 [info]: ref B L0: 92.0% 6.3% 1.7% x264 [info]: ref B L1: 95.7% 4.3%
This shows the number of reference frames used for the B frames. L0 means previous and L1 means upcoming. B-frame can look in both directions.