More logic puzzles

Murdle Book 2 [2023]
I regret getting Book 2. One book is enough.
Mine is a South Asia edition. I bought it for S$24.37. Really got ripped off.

Murdoku Vol 2 [2026]
OTOH, I don't mind Murdoku Vol 2 cos it is easier and in color. I'm shallow! :-P
This is hot off the press!
There are 5 chapters, each themed around a historical setting, with theme-specific rules to add variety. Each chapter has 16 puzzles, except one with 14; they range from easy to expert. There are two more puzzles at the end to round up to 80.
Due to this format, the difficulty ramps up very fast. Only the first two puzzles are easy, followed by medium, then hard, and the last two are expert — there are ten expert level puzzles altogether.
What-if 80286 in an alternate world
Following our alt-8086, let's extend it to 80286. What will 80286 be like if it did not have segmentation?
This is very ironic, because 80286 is the quintessential 16-bit segmented processor. Its memory management is based on segmentation in Protected Mode. It would have worked very well if segments were not limited to 16-bit — 80286 uses 24-bit address, it should allow 24-bit segments.
The answer to our question is simple. Our alt-80286 will use paging for memory management in Protected Mode — brought forward by one generation.
If we use 16 kB pages, the virtual address will look like this:
|Bits|#bits|Purpose| |---|---|+--| |14 - 23|10|Page Table| |0 - 13|14|Offset|
We only need 10 bits for the Page Table, so a Page Table entry can be just 16 bits (6 bits for flags), but it is a little tight — we need 10 bits for flags, ideally — so let's use 32 bits, and we can use the same format when we move to 32-bit.
We only need 1,024 entries, so there is only one Page Table.
If we use all 4,096 entries, we can support an address space of 64 MB — needs 26-bit address bus.
That's it, we are done.
Protected Mode
For our alt-286, Real mode means paging is off. Protected mode means paging is on.
The CPU starts in Supervisor mode with paging off. The OS may set up page tables and enable paging, entering Protected mode. It then enters User mode using IRET.
Interrupts
An interrupt has its own stack, page table and PCID, different from the kernel. ISRs are not fully trusted code!
Interrupt Vector entry:
|Ofs|#bytes|Purpose| |---|---|+--| |0|2|Flags| |2|2|PCID| |4|4|Page Table addr| |8|4|Stack addr| |12|4|Call Stack addr| |16|4|Entry point|
Flags:
- Save registers? This is for convenience
- Run in supervisor mode?
- Disable interrupt?
Each Interrupt Vector is 20 bytes. Let's make it 32 bytes for future expansion.
An interrupt will always use its Page Table and stack. It will never use the process's stack.
The process's context is saved in its Context memory. This includes the return address.
The process's context address and SP are pushed to the ISR stack. User-mode SP is intended for a system call to access its parameters that are pushed on the process's stack. An ISR won't be able to use it — its Page Table will not have user memory.
Interrupt handling in x86 Protected Mode is notoriously slow. We want interrupts to be fast. I don't know if I count correctly, but we should be able to do it in < 30 clock cycles.
System calls
A system call is made using software interrupt instruction. There is no call gate, jump gate or task gate. There is no TSS (Task State Segment).
There is no need to use a dedicated SYSCALL instruction as interrupts have very little overhead compared to INT on x86.
System calls use kernel page table and stack — by definition.
Optimizing save/restore
Let's say alt-80286 has alt-80287 integrated. This means an additional 8 48-bit registers to save — a total of 48 bytes, or 24 cycles.
It is tempting to save and restore them lazily, as Intel did. FP instructions are trapped in user mode. When they are used, the OS then saves the values for the previous process and restores the values for the current process.
But this leads to LazyFP attack which uses speculative read to avoid tripping the trap. The data can then be teased out of the registers by using cache side-channel read.
A solution is to trap even for speculative read.
An alternative solution is to assign a dirty bit to each optional register. It is cleared if the register is zero. All registers are saved and restored on inter-process context switch, but clean ones are skipped, saving cycles:
- Save current process: write dirty flags, write dirty registers, skip clean ones
- Restore new process: read dirty flags, read dirty registers, clean ones are zeroed out
Moral of the story: always zero out registers after use!
Murdle for Juniors

Murdle Jr (Book 1) [2024]
Junior edition, easier for kids below 13 years old to solve. Has 40 puzzles.
It is divided into 5 sections. Each section has 8 puzzles. For the first four sections, there are two 3x3 (2 variables), two 4x4, two 3x3x3 (3 variables) and two 4x4x4 puzzles. The last section has four 4x4 (2 variables), one 3x3x3 (3 variables), one 4x4x4 and two 3x3x3 (4 variables). The last four puzzles are adult standard.

Murdle Jr: Sleuths on the Loose [2025]
This is a mystery novel. Don't buy this book if you are looking for puzzles.
It has only one 4x4x4 logic puzzle (3 variables) that is filled up gradually as the story progresses. You are given a chance to solve the puzzle at the end of the book before the reveal.
It has a bonus 3x3 puzzle (2 variables) at the end.
I knew it was a storybook, but I thought it had puzzles sprinkled throughout. I was mistaken.
I noticed my copy is for South Asia region and is not meant for export. Its MSRP is 499 Indian Rupee, which is S$6.82! I bought it for S$15.46. Its MSRP in UK is 7.99 pounds, or S$13.65.
(I checked Amazon India and it sells for 342 Ruppee, or S$4.68, there. Too bad they don't deliver to Singapore — I estimate shipping to be around S$5.)
It turns out my Murdle Book 1 is also a South Asia edition, 599 Indian Rupee (S$8.19). I bought it for S$20.38. I feel cheated. :lol: Its MSRP in UK is 14.99 pounds, or S$25.62.
It is not surprising that the same book sells much cheaper in South Asia — 1/3 to 1/2 UK MSRP. But the publisher should have at least make it harder to grey import by using a different book cover.
Why is Meta hell now?
One word, Z is desperate.
His AI is way behind.
Previously, he bet on VR. VR is nice, but it is flawed until someone invents a way to move in-place. Not just walking, but running, jumping and other movements. Not even Apple could make VR a thing, just saying.
AI was being worked on, no doubt, but apparently the R&D gamed the metrics too much. It was fine and dandy when everyone just demo'ed bits and pieces — they could get the same results by cherry-picking — but when OpenAI released ChatGPT to the public, the gap was striking. One could carry out a conversation. The other was a toy.
It was not just behind. It was flawed. So much so that they had to abandon it and start from scratch. That's how bad it was. Open source? Forget it, Z has no time for it.
Funnily enough, in the time since, Anthropic has overtaken OpenAI with its Claude LLM. ChatGPT is better with general knowledge, but Claude is better at reasoning and doing things.
Meta is also working on smart glasses. I imagine it will take off in the next few years. By then, it'll be quaint to be using mobile phones.
What-if 80386 paging
The design of 80386 paging mechanism is elegant and impeccable.
It has a 4 kB Page Directory containing 1,024 entries, each pointing to a 4 kB Page Table that contains 1,024 entries, each of which points to a 4 kB page. The symmetry is just elegant.
Except, the page size is too small — even in 1985, arguably.
Even by 1985 standards, very few programs use as little as 4 kB of code and 4 kB of data. There was no need to be granular to this degree.
Intel must have realized too, because they added large pages (4 MB) in Pentium in 1993. That was just 8 years apart. 4 MB was too large for general use, though.
Even in 1985, I'll say 16 kB would have been a better choice. 16 kB is still a reasonable — though considered the minimum — size today, imagine that.
The case against bigger page is that you waste half a page per allocation on average. This is internal fragmentation. The smaller the allocation, the more potential for waste. However, system-level allocations are usually big — run-time libraries allocate 64 kB or bigger at a time and parcel them out. Even system-level disk buffers are seldom smaller than 16 kB.
A 16 kB Page Table contains 4,096 entries (16 kB / 4) and points up to 64 MB of memory. The Page Directory contains only 64 entries.
|Bits|#bits|Purpose| |---|---|+--| |26 - 31|6|Page Directory| |14 - 25|12|Page Table| |0 - 13|14|Offset|
Large page
If we follow Pentium's approach and drop Page Table translation, we get 64 MB large page. That is way too big! (Most of the time.)
A good large size is 64 kB or 256 kB. 64 kB is kind of small for a 'large page', 256 kB barely qualifies — it is big, not large.
Format of a 256 kB page:
|Bits|#bits|Purpose| |---|---|+--| |26 - 31|6|Page Directory| |18 - 25|8|Page Table| |0 - 17|18|Offset|
The type of page is determined at the Page Directory level, so 256 kB pages must be aligned at physical 64 MB boundary and there are only 64 such regions. Once a 64 MB region is designated to use 256 kB page, the entire region must use 256 kB pages.
A big-page Page Table has only 256 entries. It is quite wasteful.
Can we support variable-size pages? Yes, but maybe in the future.
A case for >4 GB address space
4 GB is big for a single process, but we can still run short of memory in a multi-process environment!
Pentium Pro, released in 1995, supports 36-bit address space, or 64 GB of physical memory.
We need to widen the page entry to 64-bit so that we can store the upper 4 address bits. This is a one-time change. In the future, we can widen the address to 40-bit, 48-bit or even longer — though these are more likely in 64-bit systems.
A Page Table now has 2,048 entries (16 kB / 8). The Page Directory has 128 entries. There is no need for third-level Page Directory Pointers.
|Bits|#bits|Purpose| |---|---|+--| |25 - 31|7|Page Directory| |14 - 24|11|Page Table| |0 - 13|14|Offset|
We can support 36-bit address space with just two levels of page tables — with a full Page Directory of 2,048 entries.
We finally need third level to support 40-bit address space, but that is a topic for another time. :-D
Defending against Meltdown
The TLB knows whether the page is privileged. The check is done before the read. This prevents speculative read that enables Meltdown attack. By doing this, there is no need for KPTI (Kernel Page-Table Isolation).
For complete defense, the TLB must have Process-Context Identifiers (PCID) to tag processes. This truly isolates processes. PCID was originally added to avoid flushing the TLB when switching between processes.
Without hardware support, the TLB must be flushed on every context switch. Every system call requires two flushes (to kernel and from kernel).
12K Sky at Dawn

A Thousand Miles of Wind, the Sky at Dawn: Part 1 (Book 5) [2026]
First impressions: the paper is really white! Font size is standard, double line spacing and wide margin.
I've read a few chapters and my initial impression is that it feels like it is written natively in English — it does not feel translated! The Tokyopop edition is generally good, but has some awkward phrasing sometimes.
Some readers may prefer a more literal translation to preserve the original meaning, though it may not read as smoothly.
Take the title, for example. It is translated literally. It is 风之万里 . 黎明之空 in Chinese.
Part 1 mostly sets up the story. All the exciting stuff is in Part 2. You don't miss much even if you skipped this.
LTA urges buyers to be prudent in COE bidding
LTA can only 'urge' buyers to be prudent because that's all it can do — it has no means to lower COE price. Whatever it did, it always made things worse because buyers moved from cat B to cat A, driving cat A price up.
(It is no-brainer with EV cars — they can be detuned easily, and they still feel powerful due to their high torque. Who knows if they are tuned back later? LTA is not checking, for sure. This is a semi-loophole, IMO. Detuned cars should not be allowed in cat A.)
High COE price also cause existing car owners to renew their COE, hence reducing the quota for new cars. (Though you can argue that if they scrap their car and buy a new one, they will consume one quota anyway.)
If you determine whether a car is affordable based on monthly installment, then it is still affordable. A $200k car at 2.5% annual flat interest is $250k over 10 years, or $2,083 monthly. If you earn $4k and above, you will feel it is 'affordable'. $4k is not a very high bar.
Let's compare it against two other metrics.
First, price of car vs your annual income, especially your take-home pay. If the car costs the same as your annual income, it means one year out of ten years of your pay goes to your car. This is generally considered to be affordable — though still a little on the high side.
Currently, this means earning $200k per year. This is around 90th percentile. You need to be at 90th percentile to comfortably afford a car. If you earn $100k/year (70th percentile), it is two years out of ten years. If you earn $50k/year (52th percentile), that's four years — no one should be so crazy, I hope.
The second way to look at it is how long it takes you to save this amount of money. If you save $30k/year, it will take you 6.7 years to reach $200k! That's a pretty long time. Can you save $30k a year in the first place?
(It works out to be $2.5k/mth. Normally you plan to save/invest 30% of your pay.)
COE is 'efficient'. Its price is determined purely by how much people are willing to pay.
But there are two problems. First, financing that allows 'affordable' monthly installments, while ignoring total cost. Second, commercial uses that generate revenue and 'offset' the high price.
Murdoku he cross

Murdoku: 80 Murder Mystery Logic Puzzles (Vol 1) [2025]
Can see it is derived from Sudoku. Has Sudoku-like mechanics and deduction. No ongoing story, pure deduction.

Case 1
In color, very pretty! No wonder the book costs more. :lol:
There are 80 puzzles. The first seven are 6x6 tutorial grids. After one 7x7 grid, they are mainly 8x8 and 9x9 with some non-square, with the final four 12x12.
According to the author, 1 – 20 are very easy to easy, 21 – 40 are medium, 41 – 70 are hard, 71 – 80 are expert level.
A clue gives you a list of possible squares a person can be on. With every clue, you narrow down the squares. There can only be one person per row and per column. Once you are certain, you can cross out the rest of the row/column. Sometimes, all possible squares for one person are in a single row, so no one else can be on that row.
There are no hints, but the solution can be used to unblock stuck steps, because the solving sequence is usually fixed. The name of the murderer is printed right at the top, but it is not much of a spoiler — you just want to solve the puzzle logically!
Maybe because it uses visual elements and is in color, I enjoy solving this over Murdle. I'm shallow. :-P
Online puzzles
Its website has 24 playable puzzles and 22 printable puzzles. Don't know if they are refreshed periodically.
Murdling logic
The author has a Math, English literature and MFA (Master of Fine Arts) degree. Can tell from the book. It combines math logic with witty descriptions and has a running story.

Murdle Murder Mystery Logic Puzzles (Book 1) [2023]
There are 100 puzzles with four difficulty levels. If stumbled, each puzzle offers a hint.
Hint: there are hints and solutions for other puzzles on the same page, be sure to cover them to avoid spoiling the next puzzle.
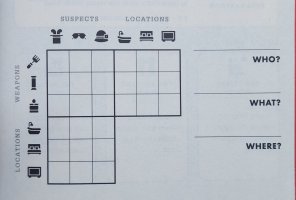
Easy has 3 suspects, 3 weapons and 3 locations. 5 – 6 clues are given, including the murder location. A basic clue either confirms or denies a fact. If it says A is at X, it rules out him being elsewhere and other people at this place — one person at one place having one object. A denial is like, A does not have P. There are more complicated clues, such as, either M or N is true.
Deduction is of the style, A is at X, X has P, thus A has P. Or, if A is not at X or Y, he must be at Z. Reminds you of Sudoku or Clue?
Medium has 2 clues and 3 statements, one of which is false (from the murderer). It has no murder location.
Hard has 4 suspects, 4 weapons, 4 locations and 4 motives. It has 9 – 10 clues, including murder location.
Impossible has 5 – 9 clues and 4 statements, one of which is false. It has no murder location.
Solving
I find it quite easy to make mistakes. To help me backtrack, I write the clue number beside a tick or cross, and whether it is deduced. Suppose I get it wrong from clue 3, I can then erase everything marked 3 and above and continue.
You do not need to fill up all the squares. As long as you fill the entire grid horizontally or vertically, you have all the info already.
Daily dose
It has its own website with daily puzzle.
A brief look at x86 paging
80386 was a 32-bit processor introduced in 1985. It had 32-bit address space. Finally, x86 was free of memory constraints — and segmentation. While segmentation was still supported, 32-bit linear address was enough for all conceivable usage. 4 GB was a magnitude bigger than typical memory configurations then — 4 MB was standard in 1992.
To illustrate, PCs started to ship with 4 GB memory in 2007 — though the 4 GB limit was felt some years before due to OS architectural design. Given how big 4 GB was, most OS split it into two — user and kernel space. It is usually 2-2 (Windows 95/NT) or 3-1 (Linux). It turned out 1 GB was not enough in later years cos it was shared across all processes.
80386 introduced paging to manage memory. This was revolutionary for x86. It could now support modern OS where fixed-size pages of memory were swapped in and out of memory as needed, giving illusion of bigger total memory.
(According to Google, 80386 was the first mass-market commercial processor to have an integrated paging-based MMU. It was even more revolutionary than I thought.)
The 80386 paging scheme is very elegant. It uses 4 kB pages, so it needs 20 bits to map a virtual address to physical address. These 20 bits are split into Page Directory and Page Table evenly.
A Page Table is 4 kB (exactly one page) and contains 1,024 entries — each entry is 32-bit. The upper 20 bits of each entry is the physical address aligned to 4 kB boundary, the lower 12 bits are control bits e.g. present, r/w permission, accessed (read?), dirty (written?), user/supervisor level and caching (enable, write-back).
More control bits are added in the future, e.g. page size (4 kB or 4 MB), global, NX (no execute).
The Page Directory is 4 kB and has 1,024 entries. Each entry is a Page Table. This allows sparse Page Tables — a fully populated Page Directory uses 4 MB (1,024 * 4 kB for each Page Directory).
PD and PT have the same format, so a PD entry can point back to PD. This technique is called recursive paging, or self-referencing page table.
Because the paging mechanism is two-level deep — needing two sequential memory reads — a TLB (Translation Lookaside Buffer) is used to cache the most recent 32 page translations, meaning locality of 128 kB of memory.
Pentium (1993) added PSE (Page Size Extension) where the 10-bit PD entry is used as the base address, the lower 22 bits are taken from the virtual address, resulting in 4 MB pages. Intel did not disclose this functionality until Pentium Pro, though.
Pentium Pro (1995) added PAE (Physical Address Extension) to support its 36-bit address space. In this mode, there is a third-level Page Directory Pointer Table that points to four PD entries. PD and PT entries are 64-bit. As a result, each page has 512 entries (4 kB / 8). A page can be either 4 kB or 2 MB (bypassing the lowest Page Table level).
Tales of Japan first impressions

Folk Tales of Japan
Given that the books were sold by Amazon.jp, I thought they would be shipped by express delivery. :lol: But then, it was 'free shipping'.
The books are smaller than I thought. I thought they were 4 x 6" — close, 4.4 x 7".
Each story is abbreviated from the original, then he gives his commentary.
I'll say it is acceptable, but that's all.
Should I have bought all four books? No. This is why I want to buy one book to try first. :lol:
S$32 for one book vs S$88 for all four. What's your choice?
What-if redesign of 8087
First, register-based instead of stack-based.
There are 8 FP registers. Each is 48-bit (4-bit type, 12-bit exponent and 32-bit mantissa in two's-complement representation and no implicit bit). The type indicates if it is a normal number, denormal, infinity, NaN, integer or pointer. This is obviously not IEEE 754 format.
Just like the redesigned 8086, it allows memory operands as source and MOV is used to write to memory.
It supports 32-bit single-precision float directly. There is no need to move it to a register first.
; fp src fadd fp0, fp1 ; 48f + 48f -> 48f fmov a, fp0 ; 48f -> 32f, default rounding ; mem src fadd fp0, b ; 48f + 32f -> 48f fmov.rz a, fp0 ; 48f -> 32f, truncate
Operations can be rounded to single-precision directly. This allows repeatable calculations in case of register spillage.
; a = b + c + d fmov fp0, b ; 32f -> 48f fadd fp0, c ; 48f + 32f -> 48f fadd fp0, d ; 48f + 32f -> 48f fmov a, fp0 ; 48f -> 32f, default rounding ; a = b + c + d (single precision) fmov fp0, b ; 32f -> 48f fadd.r fp0, c ; 48f + 32f -> 48f (default rounding to 32f) fadd.r fp0, d ; 48f + 32f -> 48f (default rounding to 32f) fmov a, fp0 ; 48f -> 32f, default rounding
Conversion operations can specify rounding mode. This is useful for float-to-int conversion (truncate towards zero) when the default is round-to-nearest.
fcnvint dx:ax, fp0 ; convert to 32-bit int (implicit .rz) fcnvint.r dx:ax, fp0 ; convert to 32-bit int w/ default rounding
Rounding modes are: nearest even (.re), zero (.rz), up (.ru), down (.rd). .r uses the default (normally set to .re).
Only basic arithmetic operations are provided, as well as FMULADD — this must be in, no matter what! — FRECIPORAL and FSQRT.
Special values
Denormals use the full mantissa. The difference from normal numbers is that the top bit is 0. Exponent is set to -2^11.
Infinity uses the top bit of the mantissa as the sign. The rest of the mantissa is not used, but should be set to 0. Exponent is set to 2^11 - 1.
For NaN, exponent and mantissa are not used, but they should be set to 0.
Integer and Pointer types are for "NaN-boxing". Integer allows 44-bit integer to be stored in exponent and mantissa. Pointer allows 44-bit pointer. It is separate so that second-level decoding is not needed.
Double precision
The problem with floating-point math is that we cannot use single precision floating-point instructions as building blocks to obtain higher precision floating-point numbers — well, we can, but they are not in double precision format.
We either need to support it natively, or have floating-point emulation friendly instructions such as CMOV (conditional move), CNTLZ (count leading zero) and SHLD/SHRD (shift left/right double).
An eye on the future
Vectorization, different formats (64-bit double precision, various 16-bit half-prec, various 8-bit, Posits).
Revelation on interstellar travel
After listening to many AI Richard Feynman videos why aliens cannnot visit us due to the immerse distance involved — where even light speed is slow — it suddenly dawned to me that we are boxing ourselves to 'reality', that is why it is impossible.
Long story short, we have not found aliens because we are doing it wrong. In our reality, it seems obvious to use radio waves and use HI line as indicator of intelligent life.
But no advanced civilizations do it this way. It is simply too inefficient — primitive, even.
What is the way to communicate — and travel? It is through higher dimensions. If a civilization does not know how to do this, they are not qualified. Such as us.
Once we breakthrough, we may find the Universe to be quite boisterous!
In an unrelated news, the third part of FF7 Remake was announced: FF7 Revelation. Many people were sure it was going to be called Reunion.
Book time!
Folk Tales of Japan
I happened upon some skits on YouTube by Kyota Ko and they were entertaining — and educational. He did the skits to encourage people to buy his books. I intended to pick up one book — maybe two — first, but ended up buying all four.
Murdoku: 80 Murder Mystery Logic Puzzles (Vol 1)
While on Amazon.sg, this book was recommended to me. It is a logic puzzle book. It merges Sudoku-style number placement with logic grid mysteries. It piped my curiosity. Let's buy one and see first. I bought this from Blackwell because it was cheaper there.
(This is the UK edition. The US edition has purple cover and is OOS.)
Murdle Murder Mystery Logic Puzzles (Book 1)
Also recommended at the same time, this is a collection of grid-based murder-mystery logic puzzles. Again, let's try one book first.
A Thousand Miles of Wind, the Sky at Dawn: Part 1 (Book 5)
Twelve Kingdoms is being re-translated by Seven Seas Entertainment. I knew about this, but I didn't plan to buy — I already have the Tokyopop edition.
A Thousand Miles of Wind, the Sky at Dawn: Part 1 was just released — Jun 2026! This is the most 'happening' arc. I decided to buy it and try. If it is done well, I'll buy Part 2 as well (Sep 2026). I bought this from Blackwell.
I may be interested to get Shadow of the Moon, Shadow of the Sea, but only Part 2. It covers the second half of the protagonist's journey in the unfamiliar fantasy world.
Brief notes on 8087
The 8087 was designed by a numerical analysis expert and served as working proof for the IEEE 754 floating-point spec. It was revolutionary. It was released in 1980, the spec was ratified in 1985.
Before the 8087, floating-point math had proprietary formats (limiting inter-operability), lacked accurary and consistency (rounding and precision) and was mostly emulated (so ultra-slow).
The 8087 supports IEEE 754 single precision (32-bit) and double precision (64-bit) formats. Internally, it uses a stack-based 8-deep set of 80-bit FP registers. Each FP register has 1 sign bit, 15-bit exponent and 64-bit mantissa (no implicit bit).
Most 8087 instructions operate on ToS (Top-of-Stack). Programmers were used to operands and were unfamiliar with stack-based operations. It was a struggle to write efficient code.
The biggest issue with 8087 is its buggy stack architecture. Due to misalignment between the design and hardware teams, the hardware does not automatically spill an overflowed stack to memory-based virtual stack. It is handled as an exception which is complex and slow. Software work around it by not overflowing the stack in the first place.
Because of this, it gives unpredictable inconsistent result depending whether the calcuations are done entirely in 80-bit registers or spilled into 64-bit FP in memory (with less precision) midway — depending on compiler and optimization level.
At one point, it was thought the reliance on ST(0) made it impossible to pipeline FP operations — because they all used ST(0). But Pentium proved it was possible to do register renaming with FXCH and achieved pipelined FP operations. It was a breakthrough. From that point, x86 FP became competitive in speed with RISC CPUs.
The second issue is that explicit synchronization is needed using FWAIT. This is needed 99% of the time, so FP assembly instructions insert FWAIT automatically before the actual instruction. This is not needed from 80287 onwards as the CPU waits for the FPU automatically.
8087 runs in parallel to 8086. It is slow compared to integer operations, e.g. FADD takes 70 – 100 cycles, so it is possible to run many x86 instructions before executing the next FP operation. Question is, how many programs made use of this?
The third is emulation. Unlike 80286, 8086 does not raise a Coprocessor Absent exception that would have allowed transparent software emulation. This means the executable does not contain FP instructions directly, but must use emulator-transformed code that call emulated functions if 8087 is absent, or modified to 8087 code if present — this is an excellent use of self-modifying code.
The technique is pretty clever. The compiler emits actual 8087 code and marks them as requiring fixup (relocation), the linker transforms them into emulated calls using fixup (which is an addition) if emulator support is needed.
(This technique does require FWAIT before each FP instruction to patch properly.)
Side note. 8087 also supports 64-bit integer and 18-digit BCD operations. These are obsolete today.
SafariUni 5x25 bino

Safari Uni (观穹) 5x25 bino
Despite a different housing, it is unmistakably the same bino as VisionKing. They even have the same pouch! VK has "VisionKing" custom label on the pouch. This does not have custom label.
(VK has custom labelled shipping box and packing tape. Now, that's professional. I didn't expect this for a low-end bino.)
Brightness is fine. No noticeable dimness in day time. Same brightness as VK.
Zone of focus in the middle only, as expected. It is sharper than VK and has crispy snap-to-focus.
All lens surfaces seem coated, unsure if prism is coated — can see one white and some cream/yellow (single coated) reflection like VK. No phase coating.
Bino focusing knob claims 15° and FMC.
Twist-up eyecups have click-stops.
Measured weight is 577 g w/ front caps and w/o strap. This is heavier than all my other binos!
Claims min focus distance is 1.9 m, actual is ~3 m. This is worse than VK!
I wonder if there are two variants depending on the batch. The min focus distance is either 1.9 m or 3 m. Safari Uni got the 1.9 m one in their first batch, so they advertised as such. VK was advertised with 3 m, but mine was ~2 m.
But it's fine, no one uses this bino for macro viewing. :lol: (Note that this is a valid use-case for binos.)
VisionKing 5x25 bino

VisionKing (视界王) 5x25 bino
Brightness is fine. No noticeable dimness in day time. Looking at the sky through the objective lens at an arm's length, it is as bright as Svbony SV202. At night, seems brighter than SV202! This is possible, 5 mm exit pupil (25 / 5) vs 4 mm (32 / 8).
Zone of focus in the middle only, as expected. It is not super sharp, but is acceptable. A bit hard to achieve optimal focus due to 'mushy' focus — the focus zone is blurry.
All lens surfaces seem coated, even the objective glass. Prism is said to be uncoated. Touchlight test shows white (no coating) and cream/yellow (single coating) reflections among purple and green (multi-coating). No phase coating.
Bino focusing knob claims 15.8° and does not claim MC now. Box says FC.
Twist-up eyecups are friction-based, no clicks and a bit loose.
Measured weight is 540 g w/ front caps and w/o strap. This is heavier than most of my binos!
Claims min focus distance is 3 m, actual is ~2.1 m!
Greenfield 8086: accessing flat memory
Short of making 8086 into a 24-bit CPU, we need to add instructions to manipulate 24-bit addresses. Taking cue from pointer arithmetic, not many are needed:
- MOV.A, ADD.A, SUB.A, CMP.A
- ADC.A, SBB.A
- AND.A, OR.A
- LEA
- PUSH.A, POP.A
- MOV.H
MOV, ADD, SUB and CMP are basic operations.
ADC and SBB can be used to construct >24-bit pointers, but I don't know if they will ever be used.
Bitwise AND and OR are useful.
LEA is of course essential. There is no 16-bit variant, only 24-bit.
PUSH.A pushes 24-bit value onto the stack (as two 16-bit values) and POP.A pops two 16-bit values.
MOV.H moves a value into the upper bits of another register and vice-versa. This allows more extensive, though lengthier, operations using standard 16-bit instructions. Technically, with MOV.H, we do not need any 24-bit specific instructions, but the operations will be lengthier.
Adding to a pointer:
; w/ 24-bit instructions add.a si, 4 ; w/ 16-bit instructions mov.h ax, si add si, 4 adc ax, 0 mov.h si, ax
Calculating diff:
; Calculate si - di ; w/ 24-bit instructions mov.a ax, si sub.a ax, di ; ax (24-bit) contains the diff ; w/ 16-bit instructions mov ax, si mov.h dx, si mov.h cx, di sub ax, di sbb dx, cx ; dx:ax contains the diff
Stack operations
Remember I said SP should not be a GPR? It means we need SP specific instructions as well. Only a few are needed:
- MOV.A SP, r/m | immed
- MOV.A r/m, SP
- ADD.A SP, r/m | +/-immed
- SUB.A SP, r/m
SP can be used directly to reference stack variables:
push arg call proc ... proc: sub.a sp, N ; reserve space for local vars mov ax, [sp + N + 4] ; arg mov bx, [sp + N - N] ; first local var mov cx, [sp + N - 2] ; last local var ... add.a sp, N ; epilogue ret 2
Or via a frame pointer:
push arg call proc ... proc: push.a fx mov.a fx, sp sub.a sp, N ; reserve space for local vars mov ax, [fx + 8] ; arg mov bx, [fx - N] ; first local var mov cx, [fx - 2] ; last local var ... mov.a sp, fx ; epilogue pop.a fx ret 2
Any register that allows register indirect addressing can be used — memory is flat!
If we use a dedicated frame pointer, we end up with 7 GPRs. If we don't, then it is just as difficult to get stack trace and unwind the stack as no frame pointer — cos we don't know which is the frame pointer!
Unwinding the stack without frame pointer is a big issue on modern CPUs. Metadata is needed.
Using Return Stack
It is not common to have two explicit stacks, one solely for return address, the other for data, though modern CPUs use shadow stack or Return-Address Stack (RAS) to prevent Return Oriented Programming (ROP).
I don't see why not — it seems trivial to support it. Stack buffer overflow — whether unintentional or malicious — is a never-ending source of bug. We need a separate SP — let's call it RSP — a couple of instructions and change CALL/RET to use it.
New instructions needed:
- MOV.A RSP, r/m
- MOV.A r/m, RSP
These are privileged instructions. The Return Stack should be on special protected pages if MMU is present. There are no instructions to PUSH/POP nor manipulate the Return Stack. It is purely for CALL and RET.
To help to unwind the stack, we push SP onto the Return Stack too, so each CALL uses 8 bytes (4 for return address and 4 for SP).
CALL and RET must be paired. There is no need to restore SP because it is done automatically.
push arg call proc ... proc: sub.a sp, N ; reserve space for local vars mov ax, [sp + N] ; arg nov bx, [sp + N - N] ; first local var mov cx, [sp + N - 2] ; last local var ... ret 2 ; no epilogue needed, will restore SP
One downside is that we can no longer RET to an arbitrary address — but this is the whole point!
push.a ax ; no longer allowed ret
Efficiency
Pushing four 16-bit words on each CALL on a 16-bit CPU is inefficient. Even functions that do not use the stack pay this penalty.
Since the address space is 24-bit, we use the upper 8 bits to store the stack size in words. This allows up to 510 bytes of local variables. If more is needed, we can use 255 to mean the lower 24-bit is SP — we push two additional words in this case.
Thus, we push only two 16-bit words on the Return Stack for each CALL in most cases. If the function uses ENTER, it modifies the top 8 bits of the return address or pushes two additional 16-bit words.
Revamped code:
push arg call proc proc: enter N ; reserve space for local vars, updates Return Stack mov ax, [sp + N] ; arg nov bx, [sp + N - N] ; first local var mov cx, [sp + N - 2] ; last local var ... ret 2 ; no epilogue needed, will restore SP
Unfortunately, this scheme does not work if we PUSH onto the stack. It is possible to make it work. This is left as an exercise for the reader. :-P
In the future, for 32-bit CPU, we will always push two 32-bit words (Return Address and SP) on the Return Stack.
Greenfield 8086: flat memory model
The first thing I'm going to get rid of is the 8086's segmented memory model — its defining characteristic!
Segmented memory model works well in the 60s and 70s, simplifying code/data relocation and is a cheap way to provide protection in multi-process environment.
It works well as long as your data fits within a segment. Once exceed, it is painful.
With hindsight, we can see segmentation falling out of favour with paging being the choice of memory management.
8086 also has a bigger address space (20-bit) than its register size (16-bit), so it is difficult to address the entire space.
80286 — nearly flat memory
80286 uses segment selectors instead of physical segments in Protected Mode. The segment registers index into a Descriptor Table that contains the base of the segment, among others.
If the upper bits of a logicial address go directly into the lower bits of the selector, we can access >64 kB almost seamlessly.
But Intel put 3 control bits at the bottom, so complicated pointer arithmetic was needed again (need to +8 to increment to next selector).
; ideal sel:ofs 0000:ffff + 1 -> 0001:0000 ; 286 0000:ffff + 1 -> 0008:0000
It is not 100% seamless — a single element cannot span segments, so >64 kB data has to be accessed carefully. Maybe this was why Intel purposely made selectors non-contiguous — you needed special handling code anyway.
Anyway, this is water under the bridge.
Other ways
The alternative to segmentation is flat memory. We need to either widen register size or use paired-registers.
Instead of 16-bit registers, we will have 20-bit registers. This allows us to put a full address in a register and dereference it directly. But this raises a question. How do we manipulate these 20-bit registers? Does it mean it is a 20-bit CPU now?
The other approach is to use paired registers. This is a common approach. 8-bit CPUs pair two 8-bit registers to access 16-bit memory space. But the 8086 has only 8 registers. Pairing them means we only have 4 — typically we need 2 – 3 pointers at the same time, so we only 4 – 2 registers left.
I'll go for the widened register approach. Instead of 20-bit, let's go for 24-bit — giving 16 MB address space. All registers are 24-bit. The CPU remains 16-bit. Most instructions manipulate 16-bit data, but some manipulate 24-bit — for pointer arithmetic.
With linear addressing, there is no more memory models. All pointers are FAR, indirect jumps/calls are FAR and all function returns are FAR. We are free from the 64 kB barrier.
The stack is also free of its 64 kB limit (though stacks seldom grow this big), but more importantly, any register can now reference the stack directly.
This does increase pointer size from 2 to 4 bytes. This makes the ISA unsuitable for systems with 64 kB or less since they only need 2-byte offsets. Once we get above a threshold, say 128 kB, the overhead no longer matters.
Another con is that we need a big relocation table. In the absence of paging and running each process in its own isolated memory space, all global code/data references need to be relocated.
A possibility is to use Global Offset Table (GOT). This makes the code PIC (Position-Independent Code) and make it reusable in multi-process environments.
What-if evolution of 8086 instruction set
The 8086 instruction set has very nice orthogonal instructions, but it also has a bunch of short instructions that use up a lot of valuable one-byte opcode space.
When Intel created the 32-bit 80386, there was really no reason to keep the same encodings — the object code needed to be regenerated anyway.
And when AMD defined the 64-bit instruction set (Intel was not interested at this point because they were creating 64-bit Itanium), they also missed the chance to redefine the encodings.
What if we could go back to the very beginning and define the instruction set properly without considering backwards compatibility with 8080/8085?
Key questions:
- 1-byte instructions?
- Load-store or reg-mem ALU operations?
- How many registers?
- Memory addressing modes
- Immediate operand?
- Displacement addressing with immediate operand?
- Misaligned mem access
- String instructions
- Size of address space
- 20-bit pointer arithmetic
- Segmented or linear addressing
- Memory-mapped or port-mapped I/O
Note that this is a 16-bit processor. We need to keep in mind future extensions like floating-point math, 32-bit and 64-bit modes, and vector instructions.
1-byte instructions?
x86 is CISC, so it will have variable-length instructions. The question is, do we want 1-byte instructions?
8086 was designed in the mid-70s and released in 1978. At that time, microcomputers had 4 kB of memory. The IBM PC shipped in 1981 with 16 kB, expandable to 64 kB on the motherboard. By 1985, it was common to fill up the entire 640 kB RAM space.
1-byte instructions are essential with 4 kB memory, not so much with 640 kB. Most x86 1-byte instructions are not high-occurrence instructions either.
Removing 1-byte instructions free up valuable opcode space that can be used for defining shorter multi-byte instructions.
Load-store or reg-mem ALU operations?
Load-store architecture is a RISC characteristic. CISC generally allows ALU operations directly on memory.
There are 3 kinds of mem ALU operations: reg-to-mem, mem-to-reg and mem-to-mem.
x86 supports the first two. It turns out that reg-to-mem (i.e. mem = mem op reg) is not good for future superscalar execution.
; load-store mov ax, [mem] add ax, bx mov [mem], ax ; mem-to-reg add bx, [mem] mov [mem], bx ; reg-to-mem add [mem], bx
How many registers?
RISC likes to have 32 GPRs, but they are an overkill — kills interrupt and context switch performance. 16 GPRs is generally sufficient, especially with register renaming. I think 8 is enough, but they must really be general-purpose!
The 8086 has 8 GPRs, but it really only has 6 — SP is not a GPR and BP is needed to access stack variables.
x86-64 uses REX prefix to expand the number of registers, among others. This is a very useful technique that can be added later.
Memory addressing modes
8086 has very limited memory addressing modes. Only 4 registers can be used for register-indirect, and only in limited ways.
80386 revamps this with SIB (scale-index-base) which is super flexible — but it is not needed most of the time.
; x86 [bx] [bx + disp] [bx + si] [bx + si + disp] ; SIB [bx * 2] [bx * 2 + disp] [si] [si + disp] [bx * 2 + si] [bx * 2 + si + disp]
Two are sufficient: register-indirect and register-indirect with offset.
With hindsight, it is very useful to have PC-relative addressing. This is used by x86-64, ARM and MIPS. It enables loading big literals (e.g. 64-bit) without making the instructions super long. It also enables PIC (Position-Independent Code).
Immediate operand?
Immediate operand increases instruction size. Do we support 1-byte and 2-byte immediates? Do we support 4-byte and 8-byte immediates in the future?
The 8086 has 1-byte and 2-bytes immediates. 80386 supports 1-byte and 4-bytes immediates. (2-bytes is supported via a size prefix, making it 3-bytes.)
Displacement addressing with immediate operand?
Displacement addressing has one optional offset (1 – 2 bytes). Immediate has 1 – 2 bytes. It adds 4 additional bytes to the instruction in 16-bit mode, but in 32-bit mode, it is 8 additional bytes. It makes for very long instructions.
Example:
mov [mem], imm
Generally, 64-bit CPUs do not have 64-bit displacement nor immediate — they make the instruction too long and they are not often used.
Misaligned mem access
As CISC, misaligned mem access is a given. However, there are times we want to enforce word-aligned access, for example, the stack, jump and call targets.
String instructions
By strings, I mean the famous LODS, STOS, SCAS, MOVS and CMPS. STOS and MOVS are especially useful when paired with REP.
They are great for manipulating strings in memory constrained systems, but we are way past that.
First, REP can be replaced by a tight loop. Next, with hindsight, MOVS is the only remaining useful instruction. The others can be written using simple instructions. For example, LODS is:
mov ax, [si] add si, 2
Size of address space
The 8086 supports 20-bit address space — 22-bit with segment registers. In the mid-70s, 1 MB address space was unimaginable. But by mid-80s, the IBM PC had already reached its limit (640 kB conventional memory).
We will widen the address space to 24-bit. 16 MB was pretty big even in the early 90s. Windows 95 required only 4 MB of memory, though it ran better with 8 MB.
Does this mean we shift the segment register by 8 bits? We want to get rid of segmentation...
20-bit pointer arithmetic
It is difficult to do 20-bit seg:ofs pointer arithmetic and comparison.
Pointer addition (up to 65536 - 16):
; convert es:di to normalized pointer mov dx, es mov ax, di shr ax, 4 add dx, ax mov es, dx and di, 0fh ; es:di is now normalized ; inc pointer by 4 (any value up to 65536 - 16) add di, 4 ; es:di is incremented, but it is not normalized
Pointer addition (any value):
; es:di -> linear pointer in dx:ax mov ax, es mov dx, ax shl ax, 4 shr dx, 12 ; dx:ax now contains 20-bit linear seg addr add ax, di adc dx, 0 ; add 32-bit ofs in cx:bx add ax, bx adc dx, cx ; dx:ax -> normalized pointer in es:di mov di, ax shr ax, 4 ; btm 12-bits of seg shl dx, 12 ; top 4-bits of seg or ax, dx ; combine them mov es, ax and di, 0fh ; es:di is now normalized
Pointer subtraction:
; ds:si -> linear pointer in dx:ax mov ax, ds mov dx, ax shl ax, 4 shr dx, 12 ; dx:ax now contains 20-bit linear seg addr add ax, si adc dx, 0 ; es:di -> linear pointer in cx:bx mov bx, es mov cx, bx shl bx, 4 shr cx, 12 ; cx:bx now contains 20-bit linear seg addr add bx, di adc cx, 0 ; find the diff in dx:ax (ds:si - es:di) sub ax, bx sbb dx, cx
It will help if the CPU can manipulate 20-bit pointers (24-bit with our design) directly. It will also help to have an extra segment register so that DS can point to the global data segment all the time.
Addition with CPU assistance:
mov dx:ax, [p] ptr.p2l dx:ax ; phy->linear addr add ax, bx adc dx, cx ptr.l2n dx:ax ; linear->normalized les di, dx:ax ; es:di -> dx:ax
Subtraction:
mov dx:ax, [p1] ptr.p2l dx:ax mov cx:bx, [p2] ptr.p2l cx:bx sub ax, bx sbb dx, cx
Segmented or linear addressing
Segmentation allows relocatable code and data without load-time fixup. It does not affect code much, but it is difficult to work with data bigger than 64 kB.
If we want linear addressing, we either need to widen the register size or use register-pairs for memory addressing.
Example of linear addressing:
; p1 and p2 are linear pointers ; *p2++ = *p1++ mov ex:si, [p1] mov ax, [ex:si] ; paired-reg is automatically linear add si, 2 adc ex, 0 mov [p1], ex:si mov ex:si, [p2] mov [ex:si], ax add si, 2 adc ex, 0 mov [p2], ex:si
Pointer manipulation is a pain when address space (20 – 24 bits) > register size (16-bit). The problem goes away with 32-bit — both address space and register size match, and address space is big enough for most use-cases.
Memory-mapped or port-mapped I/O
8086 uses a separate 64 kB port-mapped I/O address space. If we expand the memory size to 16 MB, we can just use memory-mapped I/O. With hindsight, everyone uses MMIO nowadays.
A popular pattern with port-mapped I/O is to select the index, then read/write the value. This is to reduce I/O ports used — the IBM PC has only 1,024 I/O addresses as it uses 10-bit I/O address on the 8-bit ISA bus (*). With memory-mapped I/O, we just access the I/O registers directly.
; Port I/O mov dx, 0x3d4 ; CGA CRTC index reg mov al, 0 ; 0 = Horizontal Total Register out dx, al inc dx ; CGA CRTC data reg mov al, 0x38 ; value out dx, al ; Mem I/O mov ax, CGA_CRTC_REG_BASE mov es, ax mov es:[CGA_CRTC_HORZ_TOTAL_REG], 0x38
(*) IBM expanded the ISA bus to use 16-bit I/O address with IBM AT, but there were many I/O cards doing 10-bit decoding, so it was not safe to use higher address space — unless you reserved the range in the lower address space first. IBM should have put a compatibility jumper beside each slot that disables access if the higher address bits are non-zero.
Also, memory-mapped I/O gives the expectation that I/O can be read back. Nightmare of CGA where many registers are write-only.